
Lessons from running pricing experiments at Airtable
After the recent Anthropic backlash around their pricing experiments, it felt like a good time to finally write down some of my learnings from when I was the tech lead on the monetization growth team at Airtable.
Here’s what I’ll cover:
- Pricing experiments risks. You can mitigate them to a certain extent but at the expense of learnings.
- Target metrics & guardrails. How to choose target metrics. ARR vs number of upgrades differ more than you think.
- Lower price plans can cannibalize revenue but it is also where we saw one of our biggest wins.
- Self-serve is a funnel for enterprise. The tension as the enterprise side eclipses the self-serve side.
- Pricing doesn’t live in a vacuum. Even positive experiment results don’t always mean you should ship.
Backlash
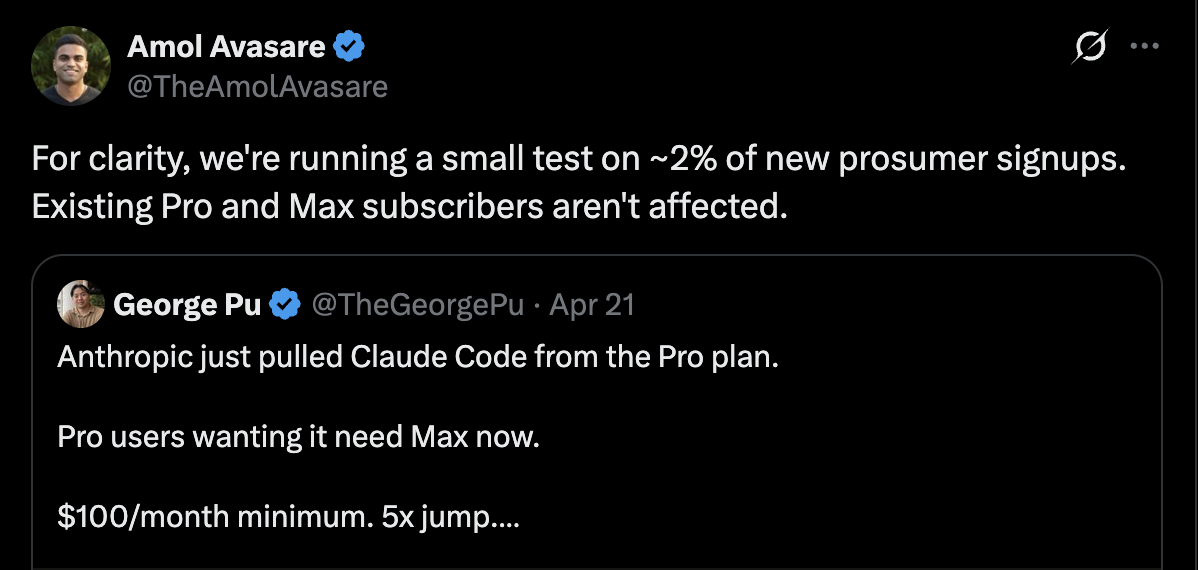
Some context in case you missed it. On Tuesday, Anthropic caught some heat after folks noticed that Claude Code was removed from the $20 Pro plan.
Amol, the head of growth, explained that it was a pricing experiment affecting roughly 2% of new prosumer signups. After the backlash though, they reverted the public facing changes.
Sam and the OpenAI team chimed in with a few spicy tweets.
Pricing experimentation risks, mitigations, and tradeoffs
Changes to pricing and packaging (aka the features/limits) can be risky. No shortage of examples of companies being on the wrong end and customers being vocal.
Before diving in, here’s a helpful high level framework to use. It comes down to two dimensions: whether the experimental plan is more or less generous than the existing ones, and whether it’ll be tested on new users only or existing ones too.
| More generous plan | Less generous plan | |
|---|---|---|
| New users only | Worse for existing users | ✅ Existing users unaffected |
| New & existing users | ✅ Best for both | Worse for existing users |
Unsurprisingly, you risk backlash when existing users are worse off. Either they’re losing value and/or they’re paying more than others for the same.
In Anthropic’s case, they actually did it right. The experiment only targeted ~2% of new prosumer signups, with existing users unaffected. However, when word got out, it was unclear this was an experiment for new users, and even then the larger concern is that this will affect existing Pro users down the line.
If this eventually does get rolled out, ideally existing users would get grandfathered in but it’s not always the case.
Besides backlash risk, there’s also revenue cannibalization risk. When testing a more generous plan with both new and existing users, existing users may switch over to the new plan potentially cannibalizing hard earned revenue.
Mitigations and tradeoffs
Given these risks, here are a few ways to mitigate them when running experiments but there are tradeoffs, often at the expense of learnings:
- Limit to new users: is the most common approach, but if the goal is to eventually roll out to existing users, you’re losing signal on key risks like cannibalization.
- Geographic testing: you can limit experiments to smaller markets but those results may not generalize to core markets.
- User segmentation: limiting to new users and geographic testing are both forms of segmentation, but there are other ways to slice it too (eg. workspace size, usage tier, use case). Same tradeoff applies, results from one segment may not generalize to others.
- Promotional framing: reduces potential backlash but muddles the signal. How much of the impact is from the promotional messaging vs the experimental plan itself (eg. limited time offer, discount for 1 year).
None of these mitigations are a silver bullet, it’s about tradeoffs. They reduce risk but they also reduce learnings. Sometimes you may start with smaller experiments to progressively build the case for a more direct experiment.
And of course, before launching an experiment be prepared that word will likely get out. Even more so for companies that are closely scrutinized. At Airtable we would monitor different channels like support, community forums, and social media.
One fun anecdote, there were some instances where we observed folks creating many accounts hoping to get into experiments to claim generous plans. This could skew results if it happens in large numbers. So to limit this kind of behavior, when folks reached out to support we would typically give them access to the experimental plan and exclude them from analysis.
Target metrics & Guardrails: ARR or number of upgrades, 6-month retention
It all starts with defining the goal. Are we trying to increase revenue, reduce churn, or grow the number of paying users (eg. land and expand).
Needless to say, different goals lead to different target metrics which leads to different experiments.
If our goal is to increase revenue, we then need to decide on the target metric. Some good candidates are ARR (annual recurring revenue) or number of upgrades. While they may seem interchangeable, they are not.
- Big workspaces can skew results: Optimizing for ARR means a single large workspace upgrading can sway the entire experiment. Optimizing for number of upgrades avoids this, but it cuts both ways, every upgrade counts the same regardless of the contract size.
- Time to run the experiment: The greater the variance in the target metric the longer it will take to run the experiment. An upgrade is a binary outcome, the workspace either upgraded or it didn’t. ARR, on the other hand, varies with contract size which means greater variance. In our case, we calculated the difference and using ARR as the target metric would require more than double the samples, essentially doubling the time to run the experiment. Of course this is less of a factor if we’re talking hours or days, more so when we’re talking weeks or months.
For those reasons, we went with number of upgrades as our target metric. It isn’t skewed as easily and converges quicker.
Next, we needed guardrail metrics to make sure we are not improving one metric at the expense of other key metrics.
The most important one is retention. An experiment that increases upgrades but meaningfully hurts retention is not a win. It means we’re converting the wrong customers. We closely monitored 3 and 6 month churn.
It takes time and patience to see the downstream effects. Larger pricing changes tend to roll out more conservatively since they don’t happen often. For smaller changes, you may choose to ship earlier if you have sufficient confidence.
Lower price plans can cannibalize revenue, but also unlock growth
As I mentioned earlier, one major concern with introducing a lower priced plan is cannibalizing revenue. Existing customers may switch over to the cheaper plan, costing you hard earned ARR.
This is different from what Anthropic is testing. They’re experimenting with removing features from an existing plan likely trying to see if it drives upgrades to their Max plan. We were mostly going in the other direction, testing whether a cheaper entry point could grow the number of paying users.
These experiments need to be designed carefully, and depending on the magnitude and scope you’d need to get buy in from the finance/strategy/c-suite.
One of my favorite experiments was a heavily discounted 5 seat plan to onboard entire teams at once. The goal was to grow the number of paid users by getting adoption in small teams which then expands over time (aka land and expand).
It required getting deep into the weeds of our homegrown billing system to support a pack of seats, but it was worth it.
This was one of our biggest wins. Without going into specifics, it was a significant increase in both the number of paid users and retention, all while holding revenue flat!
The lower price point was offset by the volume of new upgrades. Though as we’ll see, attributing the downstream expansion cleanly was easier said than done.
Self-serve is a funnel for enterprise
PLG (product led growth) companies like Slack and Airtable grew through bottoms up adoption where these self-serve users become a funnel for enterprise.
During my time at Airtable, the enterprise side of the business was growing at a much quicker rate and eclipsed the self-serve side.
There was tension regarding our goal and where to direct our efforts.
- Should we optimize self-serve plans for immediate conversion, or focus more on the fewer users that could grow to become enterprise customers?
- Should higher intent users be routed to sales earlier instead of upgrading through self-serve? Especially when there was less differentiation at the time between Pro and Enterprise plans.
- How generous should our free/entry plans be if the real value is realized later? For example, Atlassian products are typically free for the first 10 users.
It also changes how you measure results.
- Self-serve to enterprise conversions were hard to attribute cleanly, especially across different billing systems. And without cross funnel tracking, you are only seeing part of the picture.
- The impact of an experiment may not show up until months later making it hard to iterate.
It was hard navigating the transition, and we ultimately focused on growing the self-serve side with the knowledge that it would also improve the downstream enterprise funnel even if harder to track and attribute cleanly.
We also spun up a separate team focused specifically on these high potential enterprise customers.
Pricing doesn’t live in a vacuum
Taking a step back from experimentation, pricing and packaging is shaped by many factors from strategy to positioning to competition to go to market.
So even if an experiment yields positive results, it doesn’t mean it’s the right move. And ideally, these broader considerations should inform which experiments you run in the first place.
For example, removing Claude Code from Pro may result in more ARR/upgrades but long term it may be more strategic to keep it accessible on the lower price plans to nurture and grow usage, especially with fierce competition from OpenAI/Codex.
Hard to say what the goals and tradeoffs were for this specific experiment, and whether it will get rolled out. We’ll have to wait and see.
Hope you enjoyed this glimpse into the mechanics, challenges, and tradeoffs when running pricing experiments. These learnings were the work of many great people and teams.
Pricing is a deep topic and experimentation is just one part. If you’re curious to learn more, ask your favorite AI to do a deep research on the topic.