Sentiment Analysis
Github: https://github.com/omarshammas/sentiment_analysis
Authors: Omar Shammas, Tunde Agboola, Shashank Sunkavalli
Date: December 7th to 15th, 2012
Technologies: Python, MapReduce (MRJob, EMR), MPI (MPI4PY)
Algorithms: Random Forests, Decision Trees
Background
Sentiment analysis is used to determine whether a given text conveys a positive, negative or neutral sentiment. While this may seem trivial there are numerous useful applications. One can gather public opinion on a given topic by mining tweets or triage email to deal with severe or upset customers first.
Building a sentiment analysis tool requires a large annotated corpus to train the classifier. Instead of hiring turkers for sentiment analysis to build the corpus, we proposed a different approach and used ~300,000 reviews obtained from the Yelp academic dataset. While this data is not annotated with sentiment information, we assume that the star rating is an accurate measure of a review's sentiment.
After separating the dataset ⅘ for training and ⅕ for testing, we used MapReduce for preprocessing and extracting the desired features. This data was used to train a random forest classifier. Lastly, we measured our accuracy using the testing dataset.
Phase 1: Preprocess Dataset Using MapReduce
To preprocess the ~300,000 reviews we used the MRJob package that allowed us to spin up a Hadoop cluster on Amazon's Elastic MapReduce. We extracted the following 14 features from each review:
- Positive word count (based on a library of known positive words)
- Negative word count (based on a library of known negative words)
- Character count
- Count of uppercase letters
- Count of lowercase letters
- Count of punctuation characters
- Count of alphabets
- Count of numbers
- Ratio of uppercase to lowercase characters
- Ratio of alphabets to total character count
- Unigram count
- Bigram count
In addition, we calculated overall 'positivity' scores for varying n-grams. It is a tradeoff, larger n-grams provide better accuracy but require greater computational capacity. With Amazon's EMR, however, extracting larger n-grams should not be a limiting factor. We experimented with unigrams and bigrams.
- Unigram score - an overall 'positivity' score is computed based on the individual unigram scores.
- Bigram score
The individual unigram and bigram scores were computed in a pre-phase 1 stage. The 'positivity' score computed is based on the star rating of each review where that n-gram occurred. Those with fewer than 100 occurrences were ignored.
Phase 2: Build A Random Forest Classifier with MPI
A random forest classifier is an ensemble of decision trees. Each decision tree can be constructed independently making this an embarrassingly parallelizable problem. Consequently, we were able to easily incorporate MPI where each process was responsible for creating a decision tree. We used the MPI4PY package and ran our jobs on the university cluster.
As mentioned above, ⅘ of the Yelp dataset was used for training which is 240,000 reviews. To construct a decision tree, each process must perform the following steps:
- Bootstrap sampling with replacement. In other words, sample from the set of 240,000 reviews 240,000 times. Duplicates are allowed because of replacement.
- Randomly select K of 14 features without replacement, and K different thresholds between the min and max values to split the samples.
- Select the split that has the lowest gini index. In other words, select the split that best separates the samples into the different classes. A review's class is its star rating (1,2,3,4 or 5).
- Create a node in the decision tree.
- Repeat this process for each branch until the leaves at each node are of an acceptable purity. If the purity required is extremely high then you risk overfitting to the training data.
When classifying a piece of text, the random forest passes the item to each decision tree and the output is the majority vote. This may not be the optimal setup. For example, if we have 24 trees 10 of which are predicting 1 star, 7 are predicting 4 stars and 7 are predicting 5 stars. In this scenario, it may be better to select either 4 or 5 stars. It would be worthwhile to explore different setups.
Phase 3: What is our Accuracy?
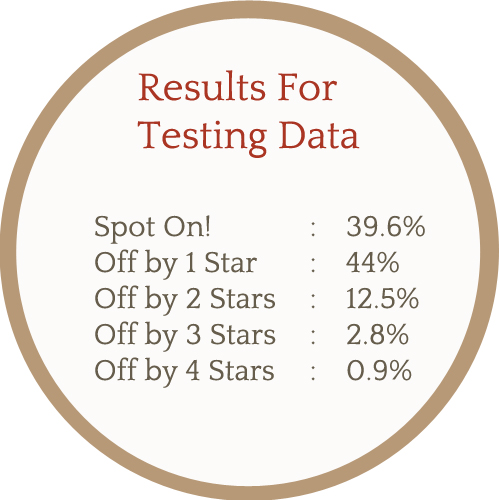
Our classifier proved to be quite reliable at predicting the star ratings, as shown below.
Improvements
As with many school projects, certain aspects will be rushed to obtain results. There are several areas for improvement and refactoring:
- While our initial assumption that a review's star rating is an accurate measure of the sentiment may seem logical, I would prefer having concrete data to support our claim.
- Experiment with different variations for combining the results from the decision trees when classifying text.
- Refactor the decision tree class to use a node class instead of a dictionary. Allows for better maintainability, cleaner code, and reduces the learning curve for programmers new to the code base.
- The system was designed to allow for CUDA to be incorporated when building the decision trees. This was never completed, and as a result its remnants should be removed from the code base or moved to a separate branch.
You can find the project here on github. If you're interested in learning about sentiment analysis and machine learning this project can be a good reference.